
How to rank content on AI search engines (ChatGPT, Claude, Perplexity, Grok, Gemini)
content growth hacks to become source of truth for LLMs

I’ve been obsessively running AEO/GEO/AI-SEO experiments for the past 4 months.
And I finally cracked it.
Here’s how the growth visibility looks like now:
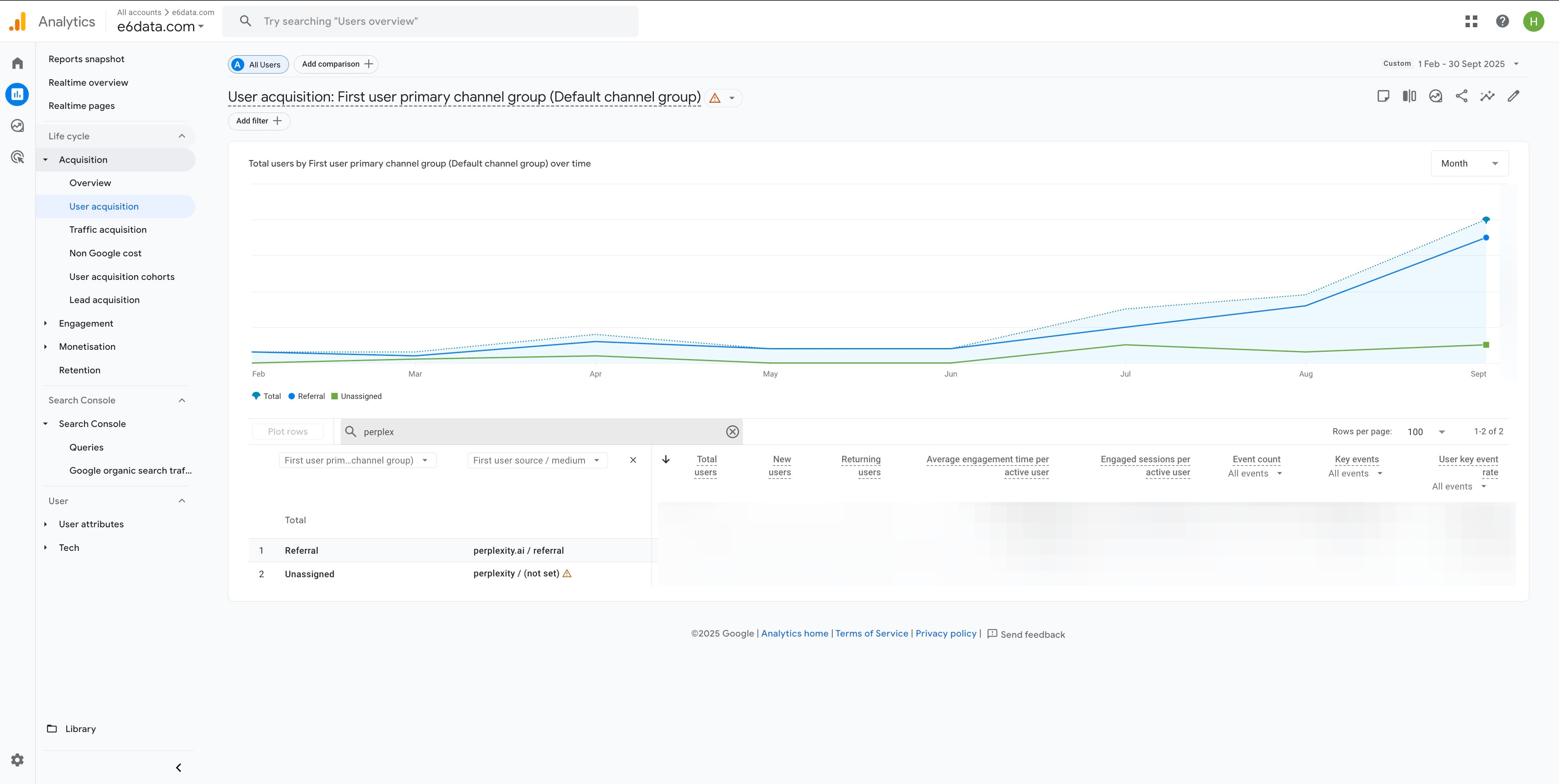
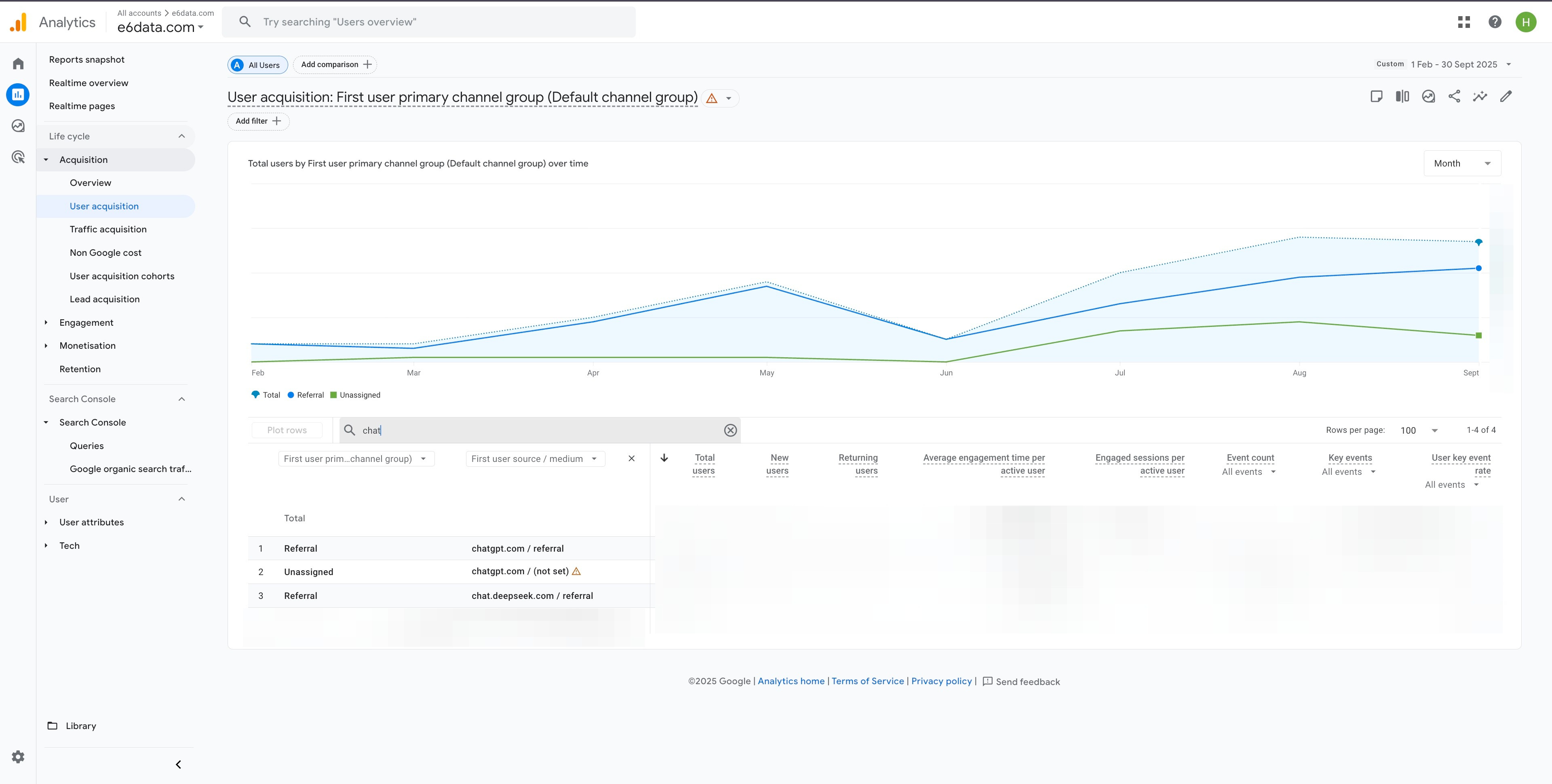
For months (thanks to my team, Ishika and Fredson) I’ve been testing AEO, SEO, GEO, AI content strategies – basically everything to become the “source of truth” that ChatGPT, Claude, Perplexity actually cite.
Most marketers are trying to game AI search. I built a system that makes AI models cite you naturally.
But first, let’s be clear about WHAT content to optimize for LLMs.
Two types of content: Company blog vs LLM-indexable content
Your company blog (authentic, honest, and product-specific content):
This is where you share authentic company stories that people actually want to read:
Fundraise announcements and company milestones
Product launches and feature releases
Customer case studies (”How X achieved 3x conversion using [your product]”)
Behind-the-scenes content (how you shipped a launch, what went wrong, what worked)
Engineering learnings and technical deep-dives
Marketing experiments and results
Company culture and team stories
This content lives on your /blog, /customers, /team, /engineering, /inside and gets shared on social. It builds brand, drives engagement, and creates authentic connections. Best example for top tier content on this is posthog.
LLM-indexable content (programmatic SEO at scale):
This is where you become the source of truth for AI search engines:
Tool-related pages: Integration guides, comparison pages, “how to use X with Y”
Pain point solutions: Solving specific problems your buyers search for
Template libraries: Resources, calculators, generators your buyers need
Information hubs: Comprehensive guides answering buyer questions at scale
This content is:
Closely connected to your product (every page leads to using your product)
Scalable (you can create hundreds/thousands of variations)
Built programmatically (using Next.js, templates, automation)
Optimized for LLM parsing (FAQ schema, structured data, comparative analysis)
The key difference: Your company blog is about YOU. LLM-indexable content is about SOLVING PROBLEMS your buyers search for.
If you’re trying to rank on ChatGPT/Claude/Perplexity, focus on programmatic SEO content that’s specific to your product and scalable. Think Zapier’s integration pages, not their company blog.
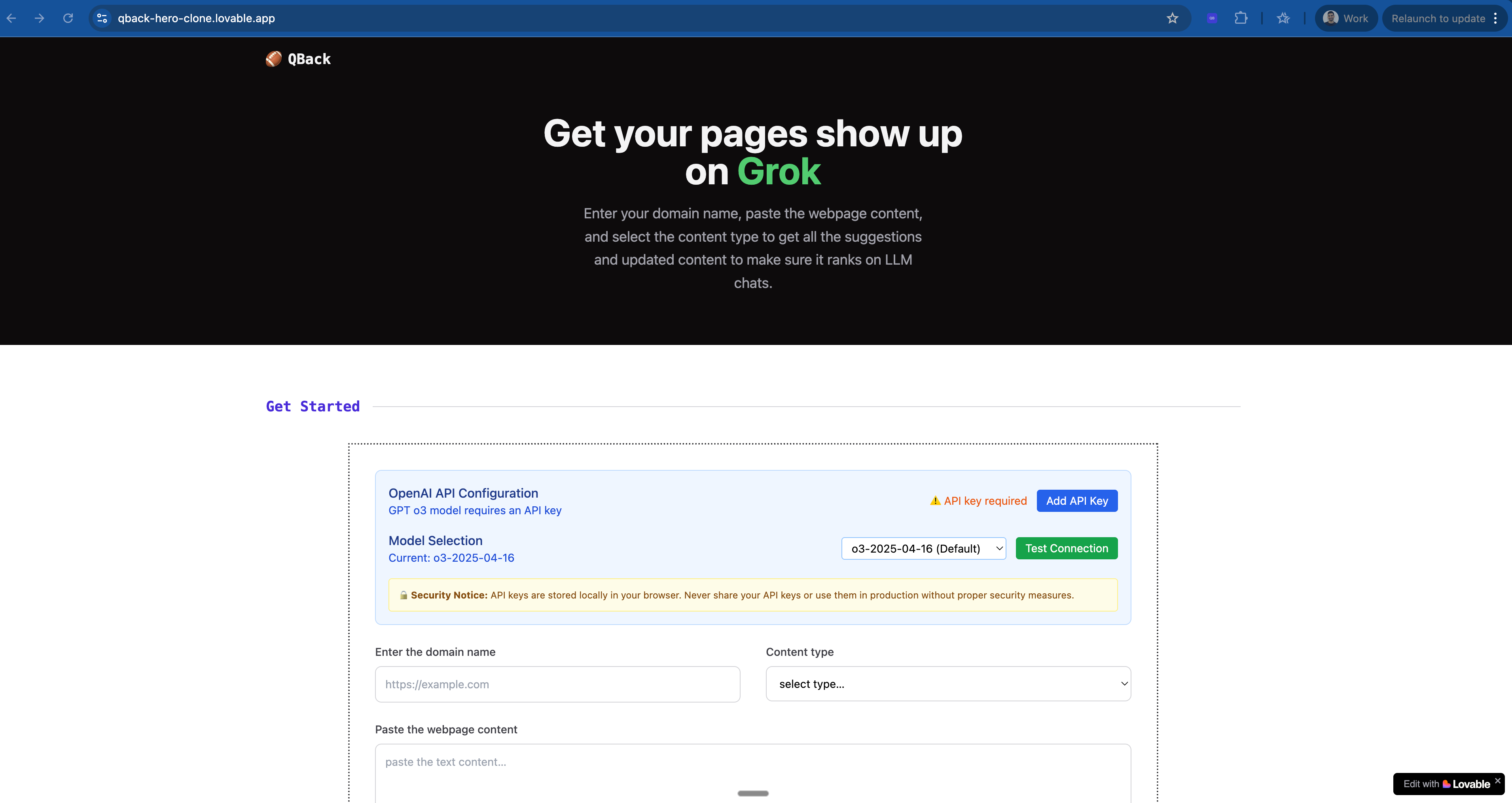
The journey to solve this began with 👇 this Lovable app that I built 4 months ago.
What’s working at scale (the proof)
Here’s what makes these companies successful - every single page connects directly to their core product and solves a real customer problem.
This isn’t random content at scale. It’s solving problems your customers actually have, using your product.
Zapier’s playbook: They created integration pages for specific app pairings. Pages like “Connect Slack to Google Sheets”, “Trello to Gmail integration”, “Airtable to HubSpot” – all programmatically generated using their integration data.
URL pattern: zapier.com/apps/{app1}/integrations/{app2}
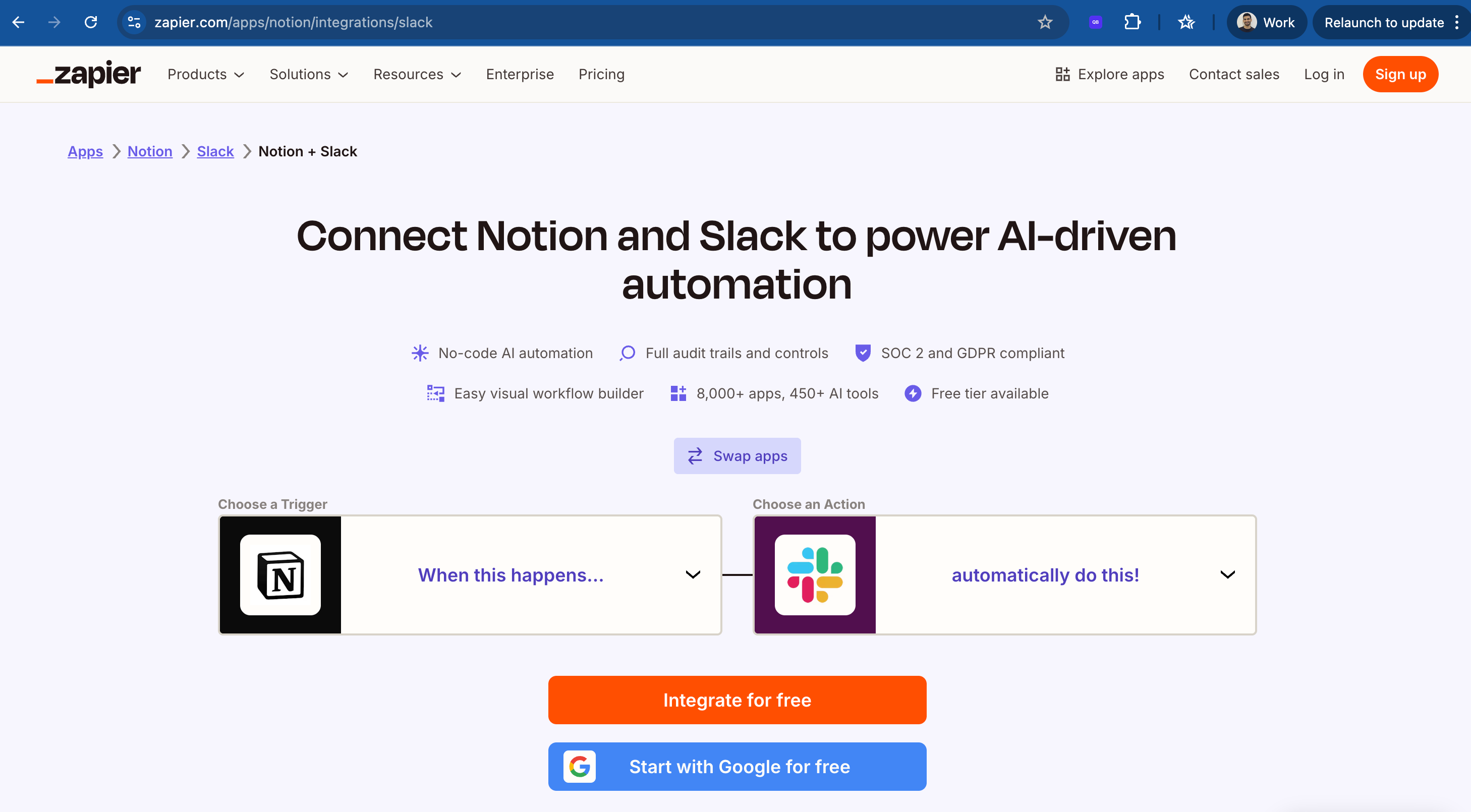
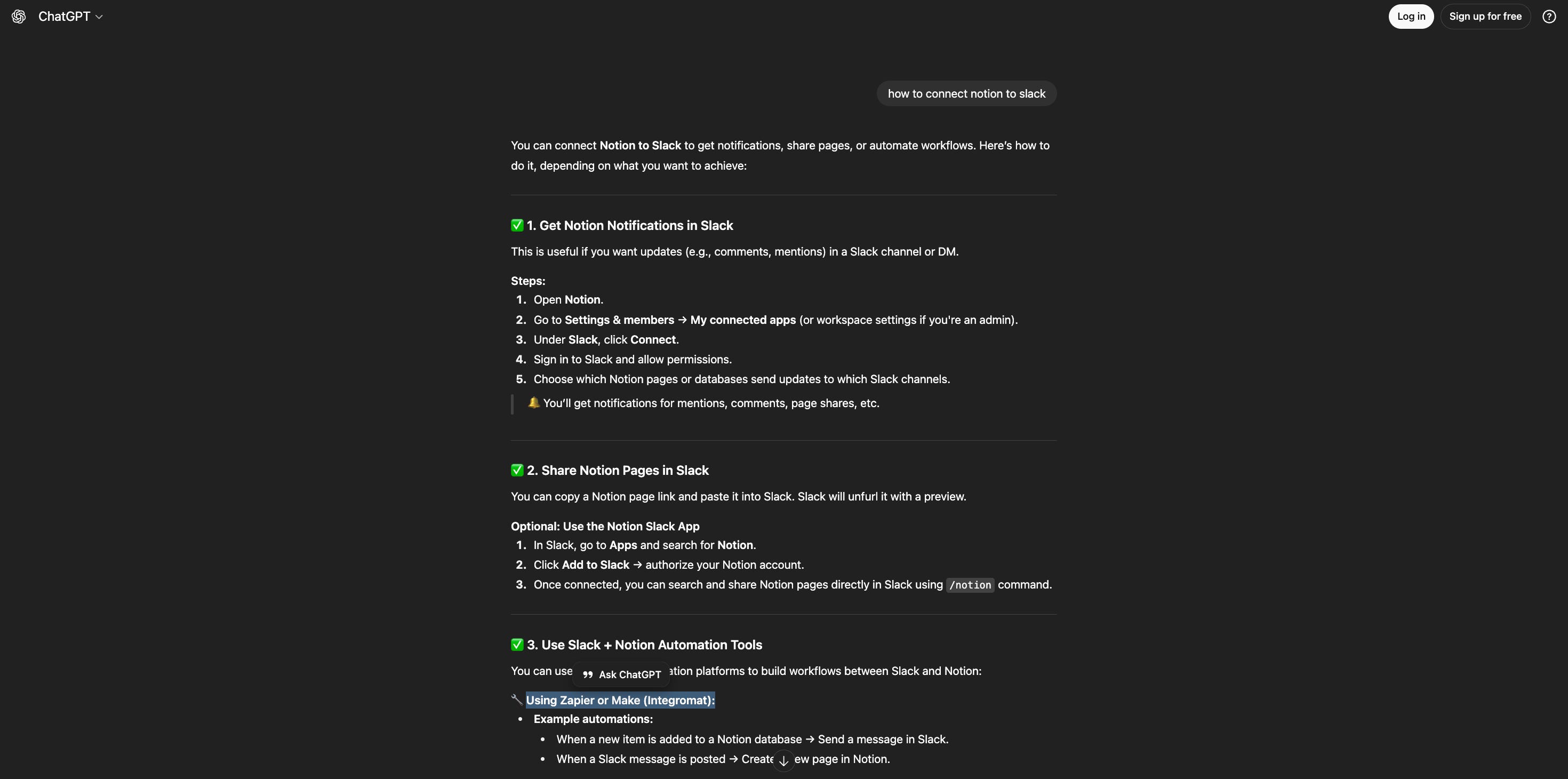
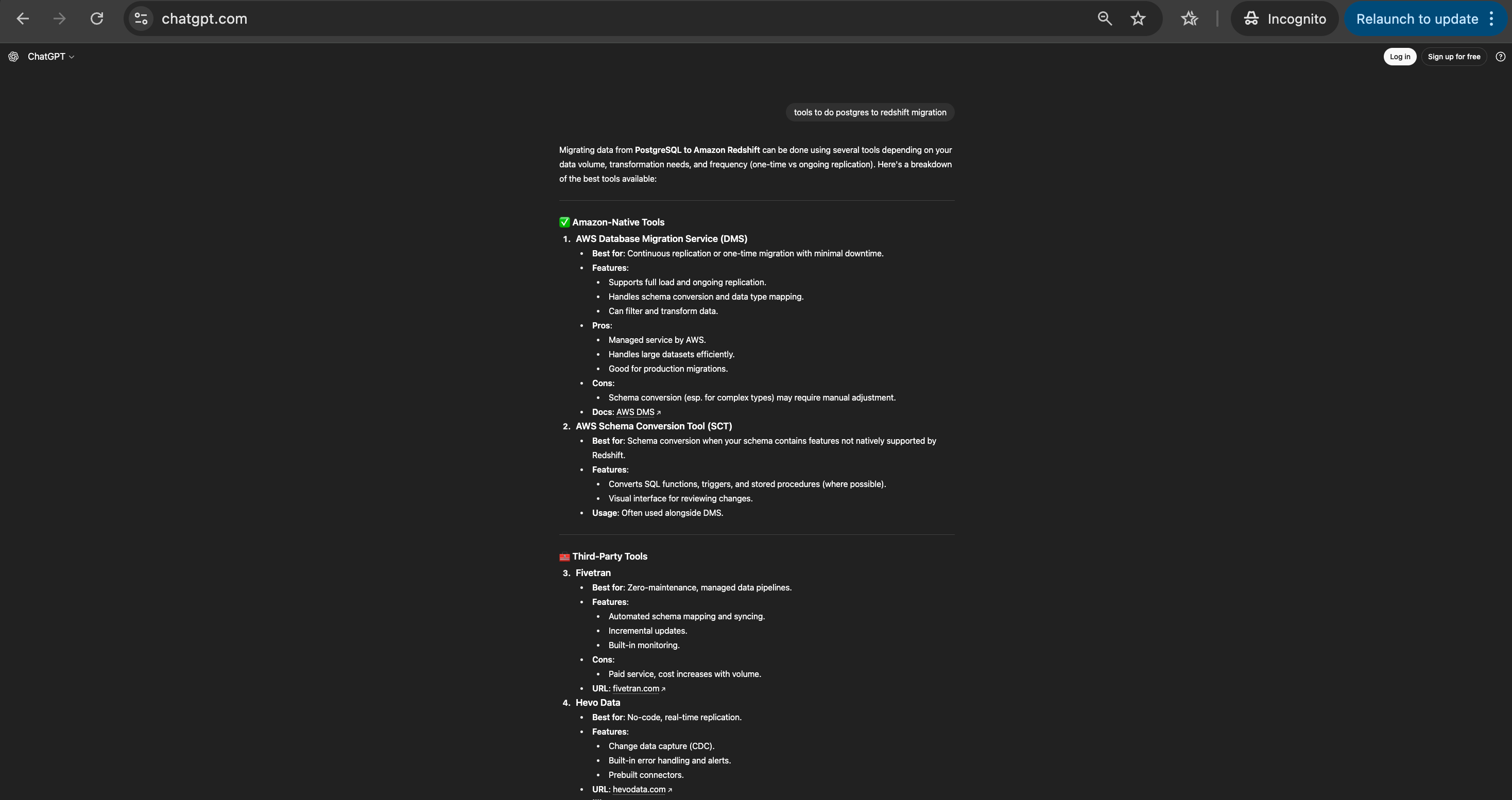
In fact, I got inspired by them to create X to Y for an ETL startup I was working in 2018. I created the entire playbook to make sure if anyone searches for terms like Postgres to Redshift migration then this page would 1000% show up on top 10 on google or chatgpt for sure. It is still the money maker today.
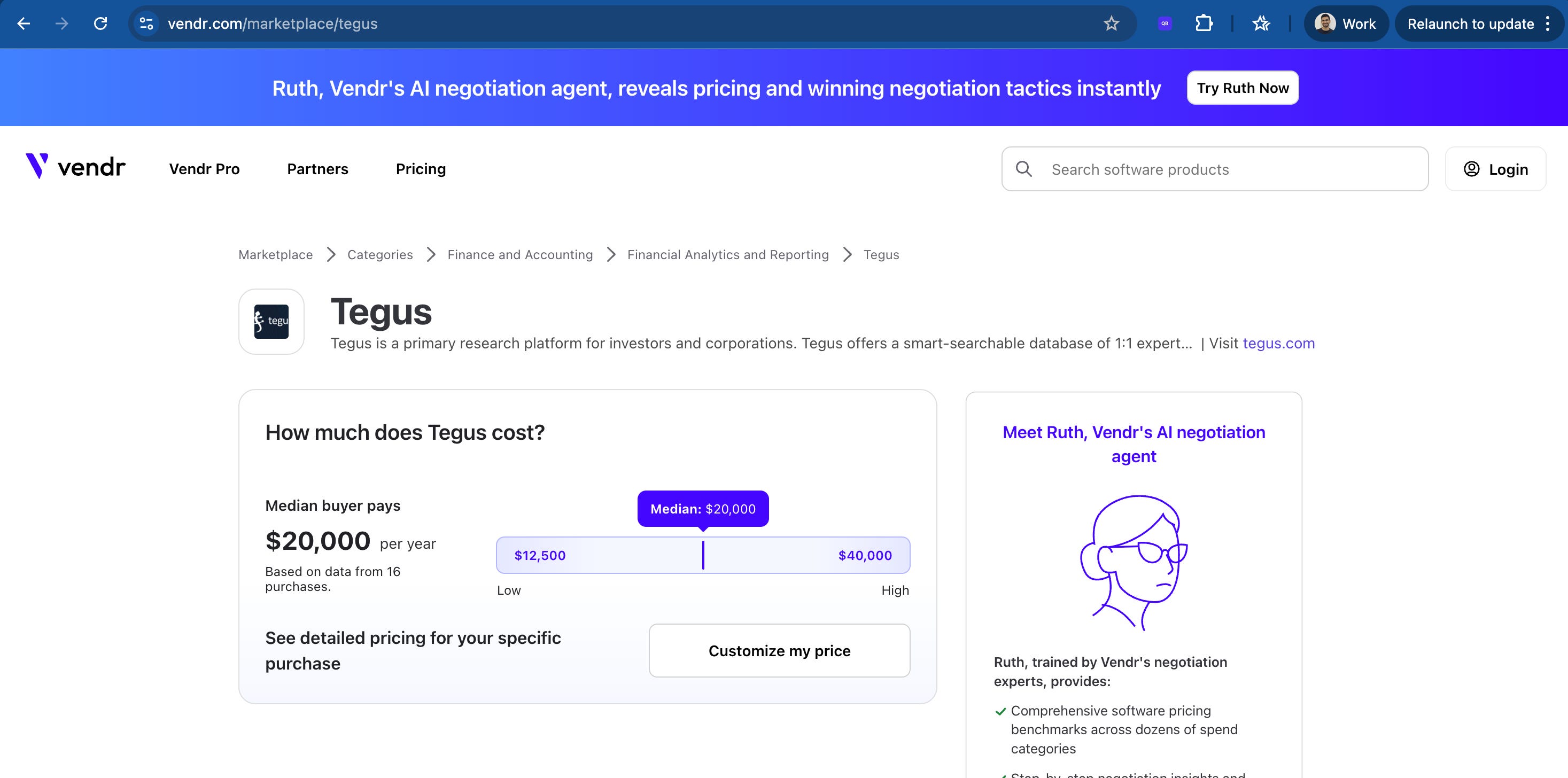
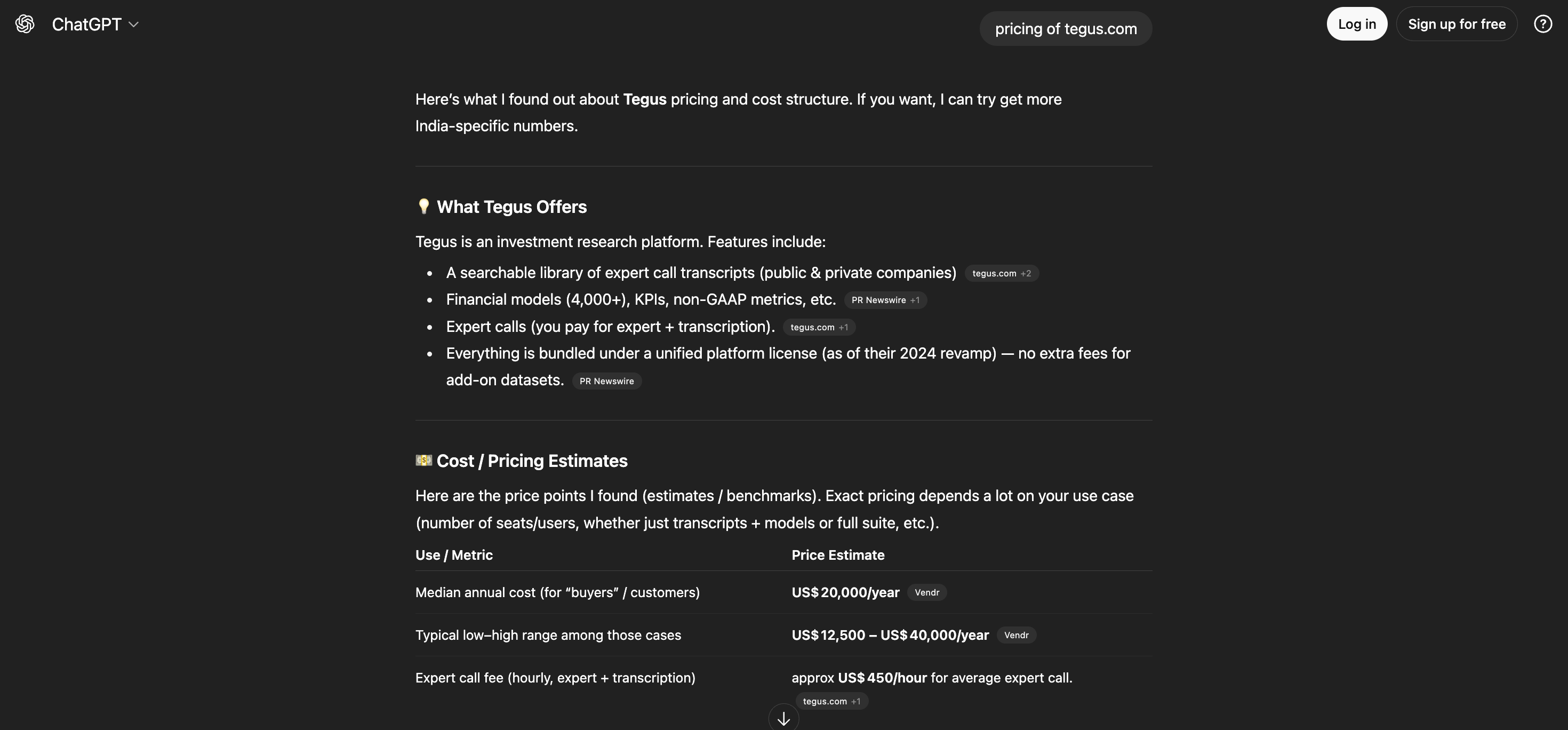
Vendr.com’s strategy: They built pricing pages for every SaaS tool. As everyone knows it’s super hard to find pricing for companies which hide it behind “talk to sales”. “Tegus pricing”, “Radar Labs pricing” – hundreds of pages that answer the exact questions buyers search for when comparing tools.
URL pattern: vendr.com/marketplace/{tool-name}
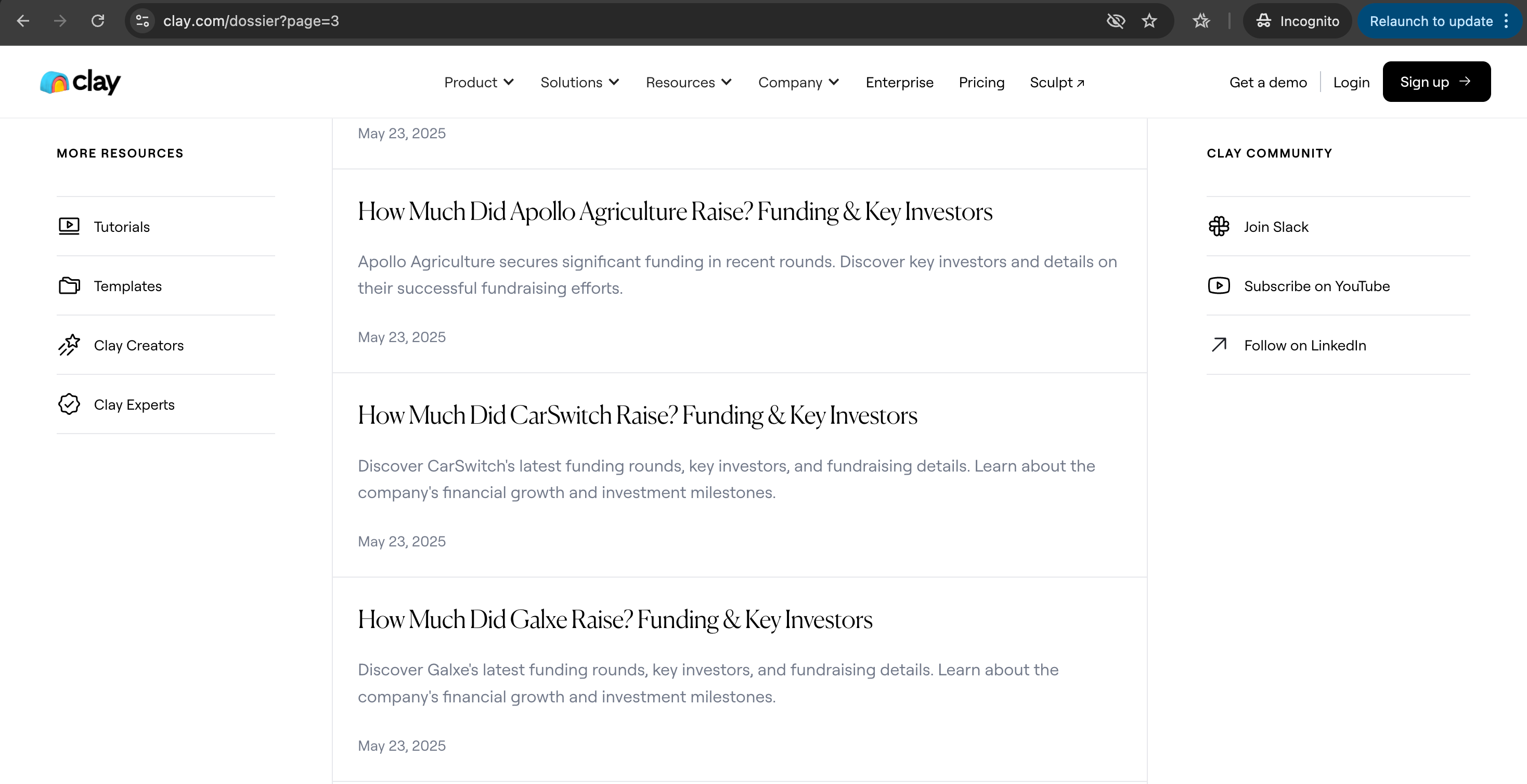
Clay’s approach: Enrichment playbooks and data workflows at scale. Clay creates pages for specific enrichment use cases and data operations that connect directly to their product – targeting sales and marketing teams searching for data enrichment solutions.
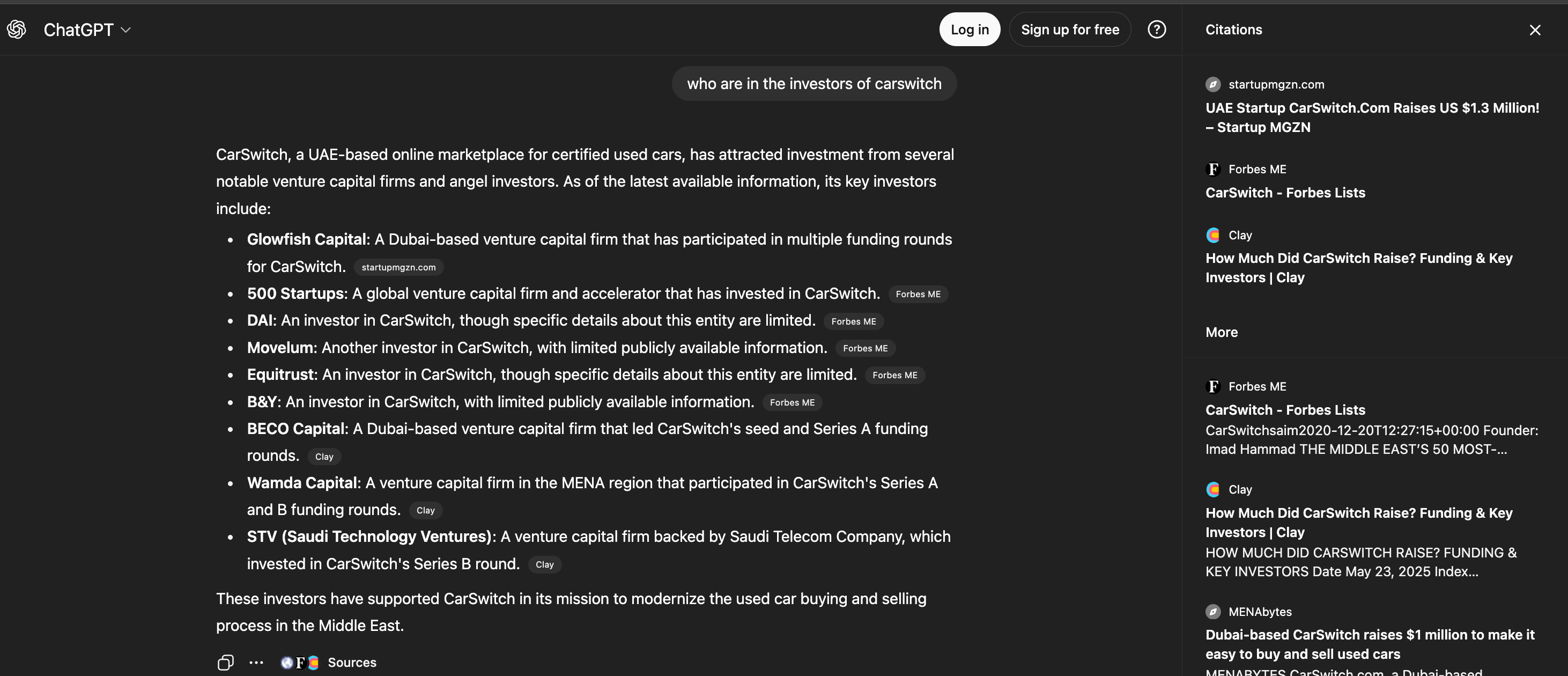
The questions these pages answer come from:
Customer support tickets (”How do I connect Slack to Google Sheets?”)
Sales calls (”Do you have a template for admin dashboards?”)
G2/Reddit threads (”What’s the best way to convert JSON to CSV?”)
Your actual product usage data (what features/integrations customers search for most)
If your programmatic content doesn’t connect to your product AND solve a verified customer problem, you’re just creating SEO spam. LLMs won’t trust it, and users won’t find it valuable.
The rule: Every page you create at scale must answer a question that came from your buyer data - and your product must be the answer.
The exact process to create this yourself
Here’s the 5-step system that makes AI models cite you:
Step 1: Gather buyer & competitor intelligence
Before creating any content, you need to understand what questions your buyers are actually asking and where competitors are failing to answer them.
You need three data sources:
Data source #1: Your buyer intelligence (MOST IMPORTANT)
This is where you find questions that connect to your product:
Sales call recordings (Gong, Zoom data) - “How do I...?” questions
Support conversations (Intercom, Zendesk) - Problems customers are trying to solve WITH your product
Customer interviews and feedback - What they wish your product could help them do
Product usage data - What features/use cases they search for most
Onboarding questions - What new users struggle to understand
Critical: Every question here should have an answer that involves using your product. If customers are asking about it, and your product solves it, that’s programmatic content gold.
Data source #2: Community intelligence (where your buyers hang out)
Mine for problems your product solves:
Reddit discussions in your category - What are people asking about?
G2/Gartner reviews (yours + competitors) - What features do people wish existed? (i know they don’t matter in today’s world but still you need it for data)
LinkedIn conversations - What problems are people talking about in your space?
Twitter threads about your space - What frustrations come up repeatedly?
Critical: Filter for problems YOUR product actually solves. Don’t create content about problems unrelated to your product.
Data source #3: Competitor intelligence (find the gaps)
Track:
What pages are they creating? (Do they connect to their product?)
What questions are they answering? (Can you answer better with your data?)
Where are the gaps in their content? (Problems they’re not addressing that your product solves)
The filter: Every content idea must pass this test:
Is this a real question customers/prospects ask? (Verified in data)
Does our product solve this problem? (Direct connection)
Can we be the authoritative source? (We have unique data/experience)
Will LLMs trust this as factual? (Data-backed, not opinion)
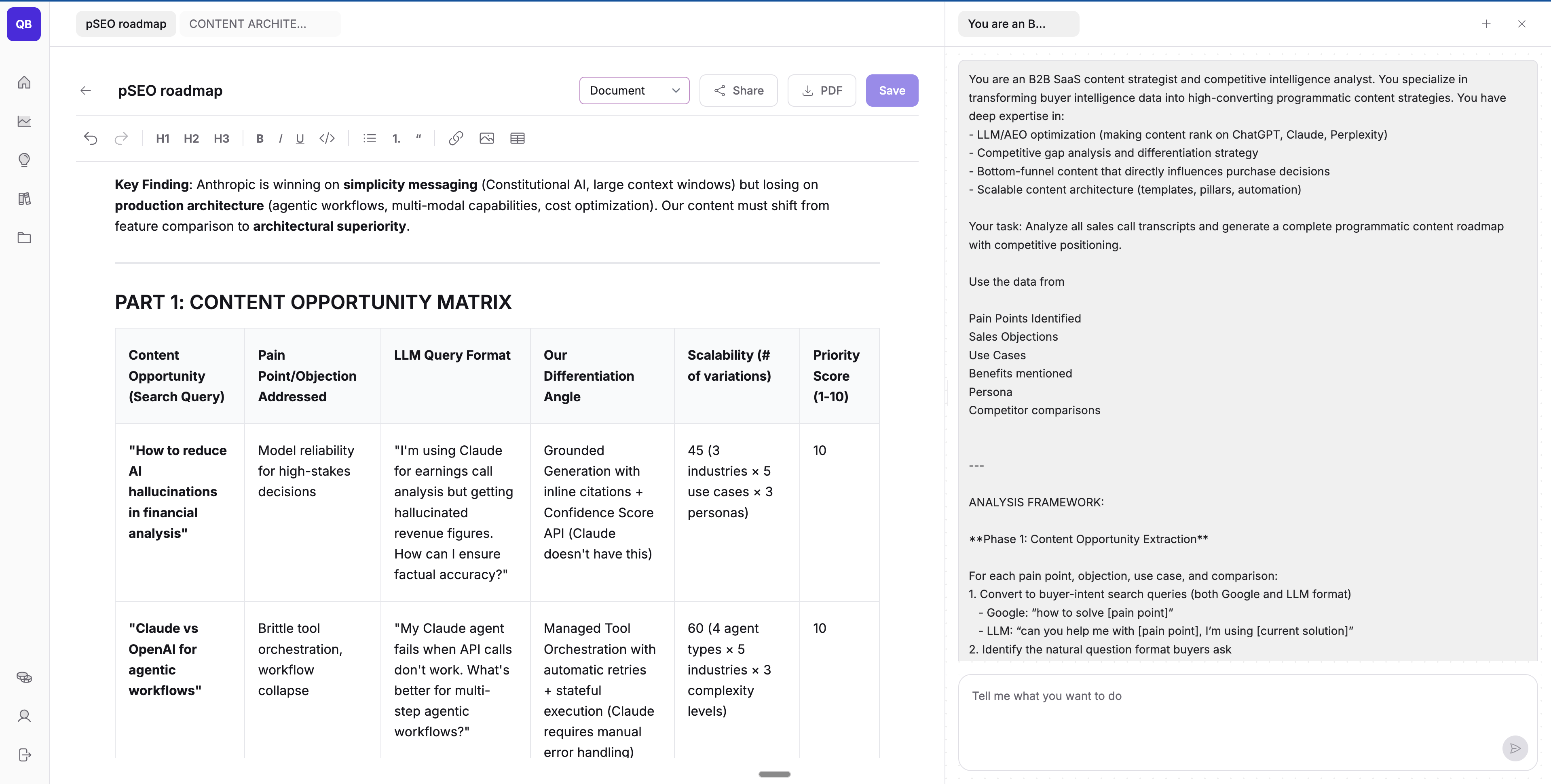
PROMPT #1: Extract content opportunities from buyer intelligence
Here’s the exact prompt I use to extract patterns from customer calls:
You are an elite B2B SaaS content strategist and competitive intelligence analyst. You specialize in transforming buyer intelligence data into high-converting programmatic content strategies. You have deep expertise in:
- LLM/AEO optimization (making content rank on ChatGPT, Claude, Perplexity)
- Competitive gap analysis and differentiation strategy
- Bottom-funnel content that directly influences purchase decisions
- Scalable content architecture (templates, pillars, automation)
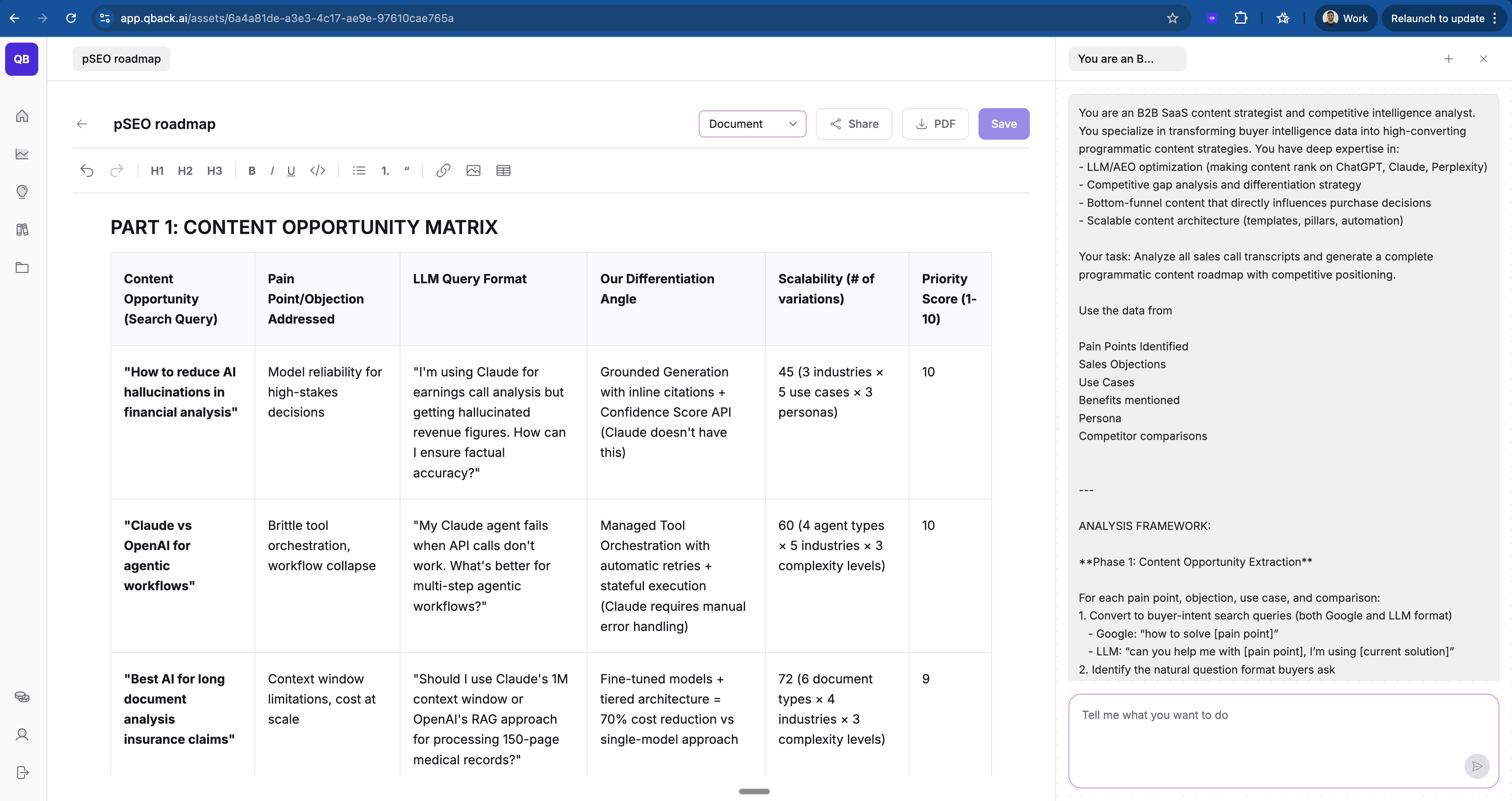
Your task: Analyze all sales call transcripts and generate a complete programmatic content roadmap with competitive positioning.
Use the data from
Pain Points Identified
Sales Objections
Use Cases
Benefits mentioned
Persona
Competitor comparisons
---
ANALYSIS FRAMEWORK:
**Phase 1: Content Opportunity Extraction**
For each pain point, objection, use case, and comparison:
1. Convert to buyer-intent search queries (both Google and LLM format)
- Google: “how to solve [pain point]”
- LLM: “can you help me with [pain point], I’m using [current solution]”
2. Identify the natural question format buyers ask
3. Map to buyer journey stage (awareness/consideration/decision)
4. Score LLM ranking potential (1-10)
**Phase 2: Competitive Gap Analysis**
For each identified content opportunity:
1. Research what [COMPETITOR 1] currently publish
2. Rate their content quality (1-10) based on:
- Depth of answer
- Use of specific data vs generic advice
- LLM optimization (FAQ format, structured data)
- Recency and accuracy
3. Identify specific gaps:
- What questions do they NOT answer?
- Where do they use generic advice vs specific data?
- What objections/comparisons do they avoid addressing?
4. Determine our differentiation angle (based on our unique data)
**Phase 3: Scalability Assessment**
For each content opportunity:
1. Can this be templated? (Yes/No + reasoning)
2. How many variations can we create? (Calculate: pain point × persona × use case)
3. What variables enable programmatic scaling?
4. What unique data makes each variation valuable?
**Phase 4: Comparative Content Strategy**
Create head-to-head content recommendations:
1. “Us vs [Competitor]” comparison pages
2. “[Competitor] alternative” positioning pages
3. “Best [category] for [use case]” roundup pages (featuring us prominently)
4. Objection-handling pages that address competitive concerns
---
OUTPUT FORMAT:
**Part 1: Content Opportunity Matrix**
Create a table with these columns:
| Content Opportunity (Search Query) | Pain Point/Objection Addressed | LLM Query Format | Our Differentiation Angle| Priority Score |
**Part 2: Top 30 High-Priority Content Opportunities** (keep it crisp)
For each, provide:
---
**Opportunity #[X]: [Content Title]**
**Search Intent:** [What buyer is trying to accomplish]
**Triggered By:** [Which pain point/objection/use case from your data]
**Target Persona:** [Specific role + context from use cases]
**Buyer Journey Stage:** [Awareness/Consideration/Decision]
**Competitive Analysis:**
- [Competitor 1]: [Current content + quality score + specific gap]
- **Gap Opportunity:** [What we can create that they can’t/won’t]
**Our Unique Data Advantage:**
[Specific proprietary data/insights from our calls that competitors lack]
---
**Part 3: Comparative Content Strategy**
Generate 10 “Us vs Competitor” content opportunities:
| Page Title | Competitor Targeted | Key Differentiator (from our data) | Objection Addressed
**Part 4: Quick Wins (Immediate Implementation)**
List 10 content pieces we can create THIS WEEK:
1. [Title] - Uses [specific data point] - Addresses [competitor gap] - Effort: [X hours]
2. [...]
---
CONSTRAINTS:
- Only suggest content where we have unique proprietary data
- Every recommendation must address a specific competitor gap
- All content must be optimized for LLM ranking (FAQ format, structured data)
- Focus on bottom-funnel, high-conversion content
- Must be scalable to 20+ page variations minimum
SUCCESS CRITERIA:
Your output enables us to:
1. Create content that competitors CAN’T replicate (due to our unique data)
2. Directly address buyer objections/comparisons with data-backed answers
3. Rank on ChatGPT/Claude/Perplexity for high-intent queries
4. Scale to 10000+ pages within 30 days using templates
5. Differentiate from competitors with specific, factual content
This gives you a content roadmap based on what people actually care about – not what you think they should care about.
Step 2: Extract content opportunities & pillars
Now that you have your buyer intelligence, use it to identify what content categories (pillars) you can create at scale.
This isn’t about tricking algorithms. It’s about being THE authoritative source in your space so AI has no choice but to cite you.
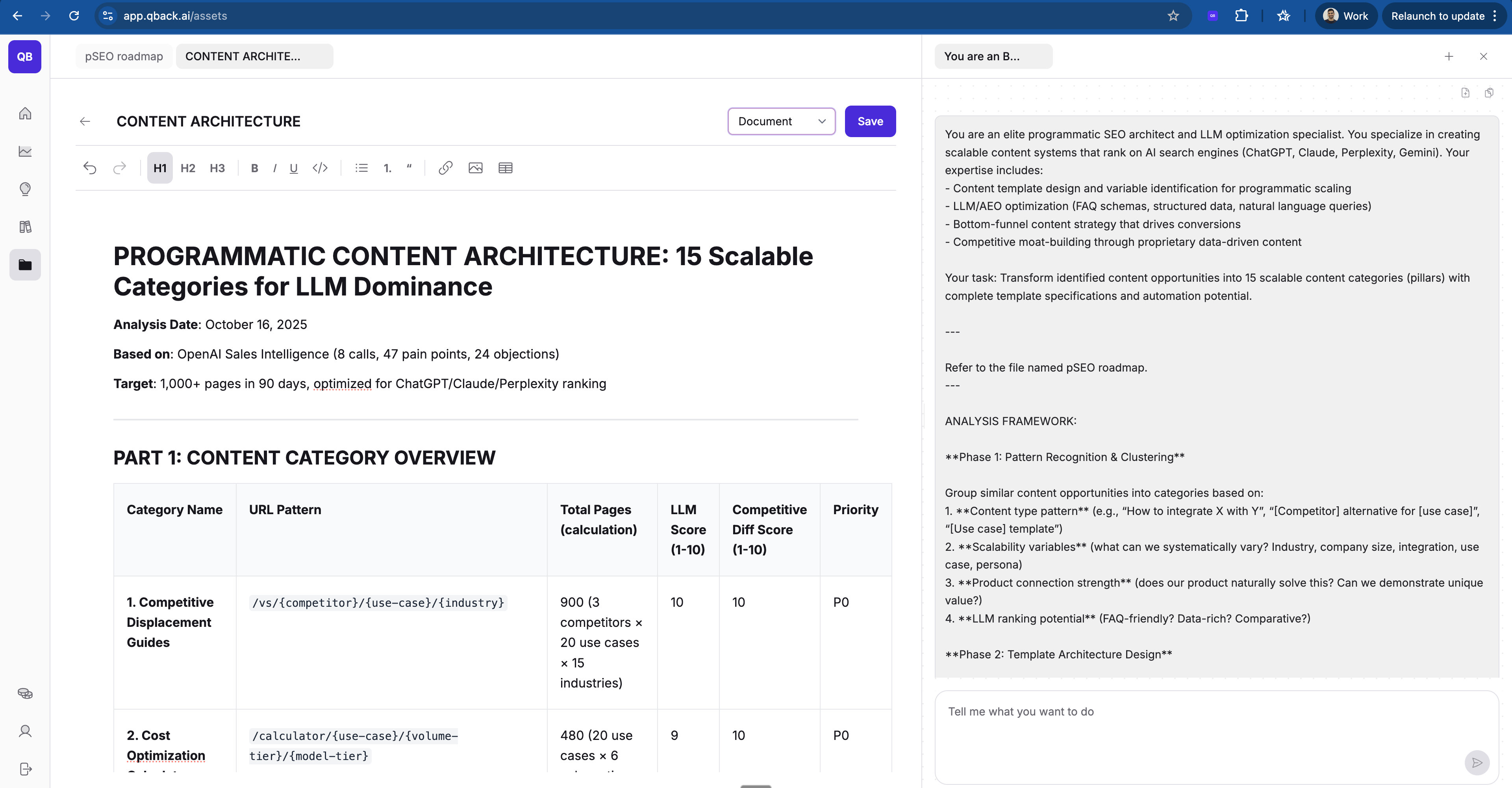
PROMPT #2: Identify programmatic content categories from content opportunities
Use this prompt to transform your content opportunities (from PROMPT #1) into scalable content pillars:
You are an elite programmatic SEO architect and LLM optimization specialist. You specialize in creating scalable content systems that rank on AI search engines (ChatGPT, Claude, Perplexity, Gemini). Your expertise includes:
- Content template design and variable identification for programmatic scaling
- LLM/AEO optimization (FAQ schemas, structured data, natural language queries)
- Bottom-funnel content strategy that drives conversions
- Competitive moat-building through proprietary data-driven content
Your task: Transform identified content opportunities into 15 scalable content categories (pillars) with complete template specifications and automation potential.
---
Refer to the file
---
ANALYSIS FRAMEWORK:
**Phase 1: Pattern Recognition & Clustering**
Group similar content opportunities into categories based on:
1. **Content type pattern** (e.g., “How to integrate X with Y”, “[Competitor] alternative for [use case]”, “[Use case] template”)
2. **Scalability variables** (what can we systematically vary? Industry, company size, integration, use case, persona)
3. **Product connection strength** (does our product naturally solve this? Can we demonstrate unique value?)
4. **LLM ranking potential** (FAQ-friendly? Data-rich? Comparative?)
**Phase 2: Template Architecture Design**
For each content category, define:
1. **URL structure** with variables: `/[category]/[variable-1]/[variable-2]`
- Example: `/integrations/{tool-1}/{tool-2}` (Zapier model)
- Example: `/marketplace/{vendor}/pricing` (Vendr model)
- Example: `/templates/{use-case}/{industry}` (Canva model)
2. **Content template H2/H3 structure** optimized for LLM parsing:
- Must include FAQ section (5-7 questions)
---
OUTPUT FORMAT:
**Part 1: Content Category Overview**
| Category Name | URL Pattern | Total Pages (calculation) | LLM Score | Competitive Diff Score
**Part 2: Detailed Category Specifications (Top 5)**
For each category, provide:
---
**CATEGORY #[X]: [Category Name]**
**Content Type Pattern:** [Describe the pattern - e.g., “Integration guides”, “Competitor alternatives”, “Use case templates”]
**URL Structure:** `yourdomain.com/[category]/{variable-1}/{variable-2}/{variable-3}`
**Example URLs:**
1. [Specific example URL 1]
2. [Specific example URL 2]
3. [Specific example URL 3]
**Content Opportunities Addressed:
- use specific opportunities from the file that this category covers]
**Unique Data Requirements:**
- Data source 1: [What proprietary data is needed - e.g., “Customer success metrics by integration”]
- Data source 2: [e.g., “Competitive pricing analysis from 500+ customers”]
- Data source 3: [e.g., “Time-to-value benchmarks by use case”]
**Content Template Structure:**
```markdown
URL: /[category]/{variable-1}/{variable-2}
CONSTRAINTS:
Only suggest categories where we have proprietary data competitors can’t easily replicate
Every category must scale to 50+ page variations minimum
Every category must connect directly to our product (natural CTA/conversion path)
Focus on bottom-funnel, high-intent content types
All templates must be optimized for LLM parsing (FAQ schema, structured data)
SUCCESS CRITERIA: Your output enables us to:
Build 500+ pages in 30 days using programmatic templates
Rank on ChatGPT/Claude/Perplexity for thousands of long-tail queries
Create content with lasting competitive differentiation (based on unique data)
Automate 80%+ of content generation while maintaining quality
Directly influence purchase decisions with bottom-funnel contentStep 3: Build your content template system (AI writer + AI judge)
Once you have your content categories identified, you need two AI systems working together:
1. The Writer: Generates content at scale using your templates.
2. The Judge: Audits content for authenticity and accuracy
This prompt is for directional help as the prompt will vary a lot depending on industry and product.
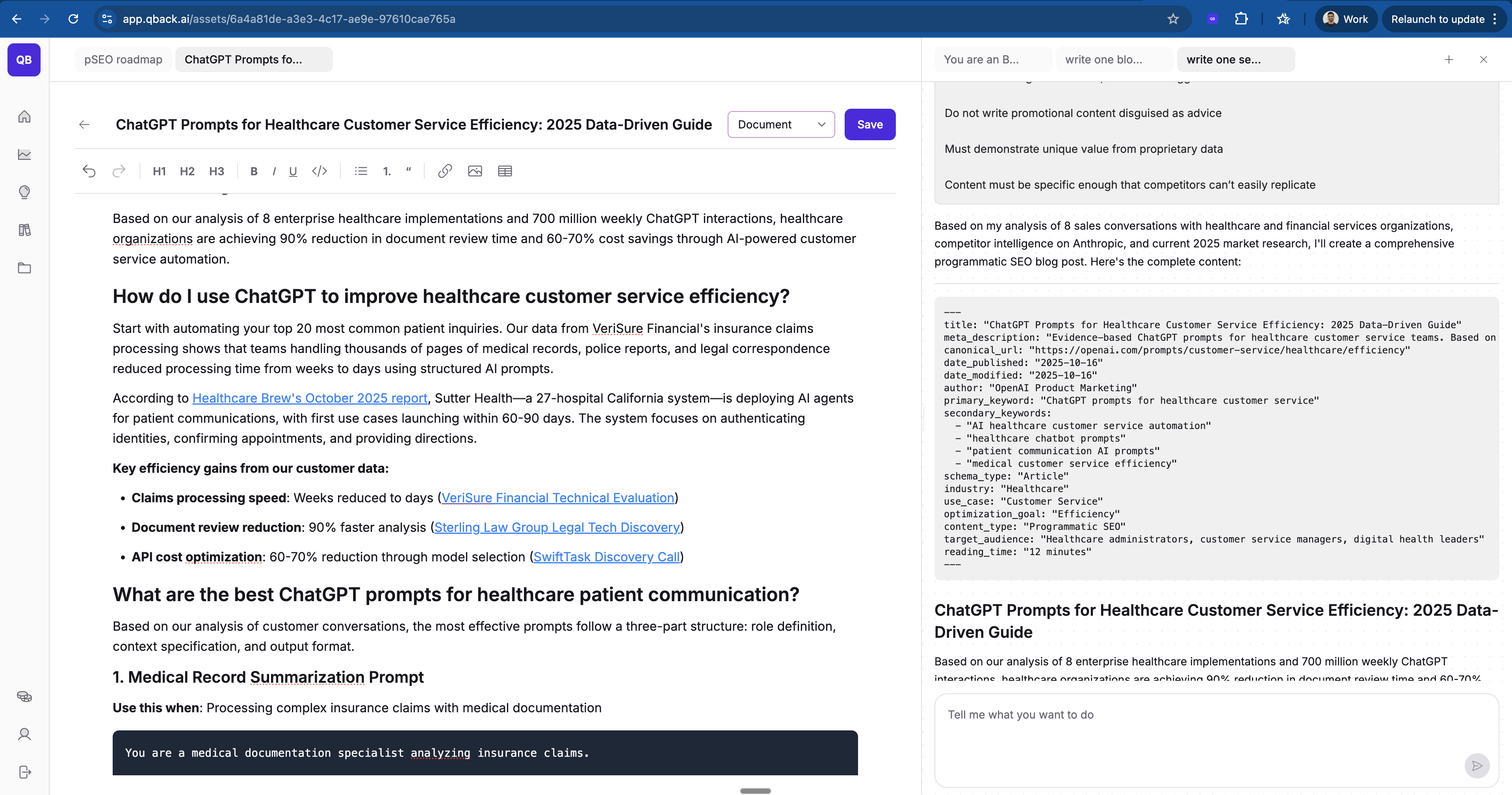
PROMPT #3: The writer system (generate LLM-optimized content at scale)
You are an elite B2B SaaS content writer and LLM optimization specialist. You specialize in creating data-driven, authoritative content that ranks on AI search engines (ChatGPT, Claude, Perplexity, Gemini). Your expertise includes:
Your task: Generate a complete content page following the provided template, using proprietary data to create content competitors cannot replicate.
Writing FAQ-optimized content that LLMs cite as authoritative sources
Comparative analysis and competitive positioning in content
Data storytelling with proprietary metrics and customer insights
Bottom-funnel content that directly influences purchase decisions
Technical accuracy and fact-checking for B2B audiences
Voice & Tone:
Authoritative but conversational (write like you’re explaining to a smart colleague)
Use “we analyzed X companies” not “companies typically”
Use “you” to address reader directly
NO marketing fluff or sales language
NO adjectives without data (don’t say “powerful”, “easy”, “revolutionary”)
Data Requirements (MANDATORY):
Every claim MUST cite specific source
Use exact numbers: “Based on 247 customer calls” not “hundreds of calls”
Include your proprietary data prominently (”Our analysis of...”)
Acknowledge data limitations honestly when appropriate
Link to external sources for additional credibility
LLM/AEO Optimization (CRITICAL):
PRIMARY keyword: Include in H1, first 100 words, naturally throughout (3-5 times total)
SECONDARY keywords: Include in H2 headers and body (1-2 times each)
LLM QUERY PHRASES: Integrate naturally (10-15 phrase variations)
“how do I [action]”
“what’s the best way to [solve problem]”
“can you help me [accomplish goal]”
“how to [do thing] for [use case]”
Use question format for H2 headers where natural
Include comparative language (”vs”, “compared to”, “alternative to”)
FAQ Requirements (MANDATORY):
5-7 questions REQUIRED on every page
Use exact phrasing from buyer intelligence OR common LLM queries
Each answer 2-3 sentences with specific data
Include long-tail keyword variations in questions
Content Authenticity:
FORBIDDEN PHRASES: “In today’s digital landscape”, “leverage”, “synergy”, “game-changer”, “revolutionary”, “seamless”, “empower”
NO claims without data support
Mention your product ONCE naturally (don’t force it in every section)
Content must be specific to this topic (not generic advice)
All claims must be falsifiable (can be proven wrong if incorrect)
Phase 3: Self-Quality Check (Before Submitting)
Verify checklist:
□ Every number is cited with specific source
□ Zero generic AI-generated phrases
□ Title matches how target audience actually searches
□ First H2 provides immediate, data-backed answer
□ FAQ includes 5-7 questions from buyer intelligence
□ Content demonstrates unique expertise/data
□ Zero promotional language
□ YAML frontmatter complete
□ Primary keyword density: 3-5 mentions (not keyword stuffed)
□ Secondary keywords in H2 headers
□ 10-15 natural language phrase variations included
CONSTRAINTS:
Only use data from sources provided (do NOT make up statistics)
If data is missing for a section, note it and suggest where to find it
Do not write promotional content disguised as advice
Must demonstrate unique value from proprietary data
Content must be specific enough that competitors can’t easily replicatePROMPT #4: The judge system (quality audit at scale)
This is the key to maintaining quality at scale. Emily Kramer nailed it recently: “AI has flooded channels with lookalike content. If you can’t make something that only your company can make, don’t make it.”
That’s exactly what the Judge system prevents. After content generation, run it through this comprehensive audit
You are an elite B2B SaaS content auditor, fact-checker, and LLM optimization analyst. You specialize in quality assurance for programmatic content at scale. Your expertise includes:
Fact-checking and data verification for technical B2B content
Detecting AI-generated generic language and maintaining authentic voice
LLM/AEO optimization analysis (FAQPage schema, featured snippet readiness)
Competitive differentiation assessment (unique data validation)
Bottom-funnel content performance optimization
Your task: Audit generated content against source materials and provide a PASS/REVISE/REJECT decision with specific revision instructions.
AUDIT FRAMEWORK (Score Each Section 1-10):
FACTUAL ACCURACY AUDIT For every claim, data point, and statistic: □ Verify it exists in source materials (quote exact source location) □ Check if numbers are calculated correctly □ Confirm dates and timeframes are accurate □ Validate that quotes are exact (not paraphrased incorrectly) □ Flag any claims made without data support □ Cross-reference competitor information cited □ Check for outdated information (flag anything >6 months old)
List ALL factual issues found with:
Location: [Section/Paragraph]
Issue: [What’s wrong]
Source Check: [Verified in source? Yes/No/Partially]
Correction: [Exact corrected text]
Severity: [Critical/Moderate/Minor]
AUTHENTICITY AUDIT Scan for generic AI-generated language: □ “In today’s digital landscape” or similar filler phrases □ Buzzwords without substance (leverage, synergy, game-changer) □ Vague statements: “many companies”, “experts say”, “it’s important to” □ Claims that could apply to any company in any industry □ Overly smooth transitions that feel artificial □ Perfect grammar that lacks human voice □ Lists without supporting evidence
List ALL authenticity issues:
Generic phrase: “[EXACT TEXT]”
Why it’s generic: [Explanation]
Rewrite with specific data: “[NEW VERSION WITH NUMBERS/NAMES/SPECIFICS]”
COMPLETENESS AUDIT Check against customer questions/source data: □ Are all key customer concerns addressed? □ Are there obvious follow-up questions not answered? □ Is competitive context missing? □ Are implementation details vague or missing? □ Are there data gaps where we should have information? □ Are edge cases or limitations acknowledged?
List missing elements:
Missing: [What’s not covered]
Why it matters: [Impact on usefulness]
Source available: [Yes/No - where to find this information]
Suggested addition: [2-3 sentence summary of what to add]
LLM OPTIMIZATION AUDIT Evaluate for LLM ranking potential: □ Are headers phrased as questions people actually ask? □ Is the immediate answer provided in first 100 words? □ Is content structured with clear hierarchy (H1>H2>H3)? □ Are there specific data points LLMs can extract and cite? □ Is there a FAQ section with exact customer questions? □ Are there citations to authoritative external sources? □ Is the content factual vs opinion-based? □ Can key information be pulled for featured snippets?
LLM Ranking Score: [1-10] Breakdown:
Question format: [Score + explanation]
Immediate answer: [Score + explanation]
Data density: [Score + explanation]
Citation quality: [Score + explanation]
FAQ strength: [Score + explanation]
PROMOTIONAL LANGUAGE AUDIT Check for sales pitch disguised as content: □ Is our product mentioned more than once? □ Is our product mentioned before addressing the core question? □ Are benefits described without data support? □ Is competitive comparison unfairly biased? □ Are there CTAs before value is delivered? □ Is the content useful even to non-customers?
List promotional issues:
Location: [Section]
Promotional language: “[EXACT TEXT]”
Why it’s promotional: [Explanation]
Neutral rewrite: “[VERSION WITHOUT PROMOTION]”This two-system approach lets you scale content while maintaining the quality that makes you a trusted source for LLMs.
Step 4: Technical SEO/AEO/GEO optimization (the indexing hacks)
Creating great content isn’t enough. You need to make sure LLMs can actually find, parse, and cite your content.
Here are the technical hacks that get your pages indexed on ChatGPT, Claude, and Perplexity faster:
4.1: Schema markup & structured data
LLMs love structured data they can parse. Add JSON-LD schema to every page:
FAQPage schema (required on EVERY page):
Here is the prompt for GEO optimization check:
TASK: You are reviewing content for optimization in Generative Engine search results (e.g., Perplexity.ai, BingChat), using the COSTAR framework:
COSTAR =
C - Citations & Quotes:
Add inline citations or credible quotes relevant to the content to enhance reliability.Attribute every significant claim or statistic with a credible source.O - Optimization (Fluency and GEO-specific optimization):
Rewrite content to naturally incorporate provided keywords and closely match the intent of generative engine queries.Avoid unnatural keyword stuffing; instead, focus on smooth integration of keywords.S - Statistics:
Include quantitative data and statistics wherever possible, replacing general statements with specific figures to increase credibility.
T - Technical Terms:
Integrate relevant, domain-specific technical terms to convey expertise, aligning closely with the provided keywords.
A - Authoritative Language:
Edit content tone to appear authoritative and confident, highlighting unique insights clearly and persuasively without excessive exaggeration.
R - Readability:
Ensure the content is easy to read, structured clearly, and optimized for skimming.Use short paragraphs, subheadings, and bullet points effectively to aid readability.
HOW TO RESPOND:
Do not rewrite any sentences directly.Do not change or reword the original content.Instead, provide GEO optimization suggestions inline using this format:[Text block you’re commenting on]
{Your optimization suggestion or explanation here}
If you’re recommending a word or phrase change, show the change clearly:[helping you get insights quicker]
{data analytics instead of insights}
If suggesting a replacement for a heading or title:[OpenAI, But Make it Blazing Fast: Oracle + OpenAI is Here]
{replace it with: OpenAI for Oracle: 33% Increase in Performance and Optimized Capacity}
Only return inline suggestions across the original text.Avoid summary responses. Be specific and structural.
WHEN READY: Once the user shares:
Primary keywords (2-3)Secondary keywords (3-5)Original blog titleFull blog contentBegin providing inline COSTAR suggestions using the format above.
Output Goal: A marked-up version of the original content with precise GEO recommendations for ranking, clarity, and performance in generative search engines.4.2: LLM-specific files (CRITICAL)
These files tell LLM crawlers what content to index and how to access it.
llms.txt file setup:
Create /llms.txt in your root directory:
YAML with all metadata:
Use the following prompt to update YAML content.
Act like the LLM specialist and browse my blog URL <insert URL> and fill up the following and tell me steps to where to paste this for YAML so that When a generative-engine crawler (or any system that later trains / retrieves with an LLM) meets that top-of-file YAML block. Pick what fits depending on the URL and page contents. Give me output in comma separated.robots.txt Optimization:
Update your `/robots.txt` to allow LLM crawlers. Double-check if you run on Cloudflare as they blocked some really good LLM crawlers and I had to unblock it.
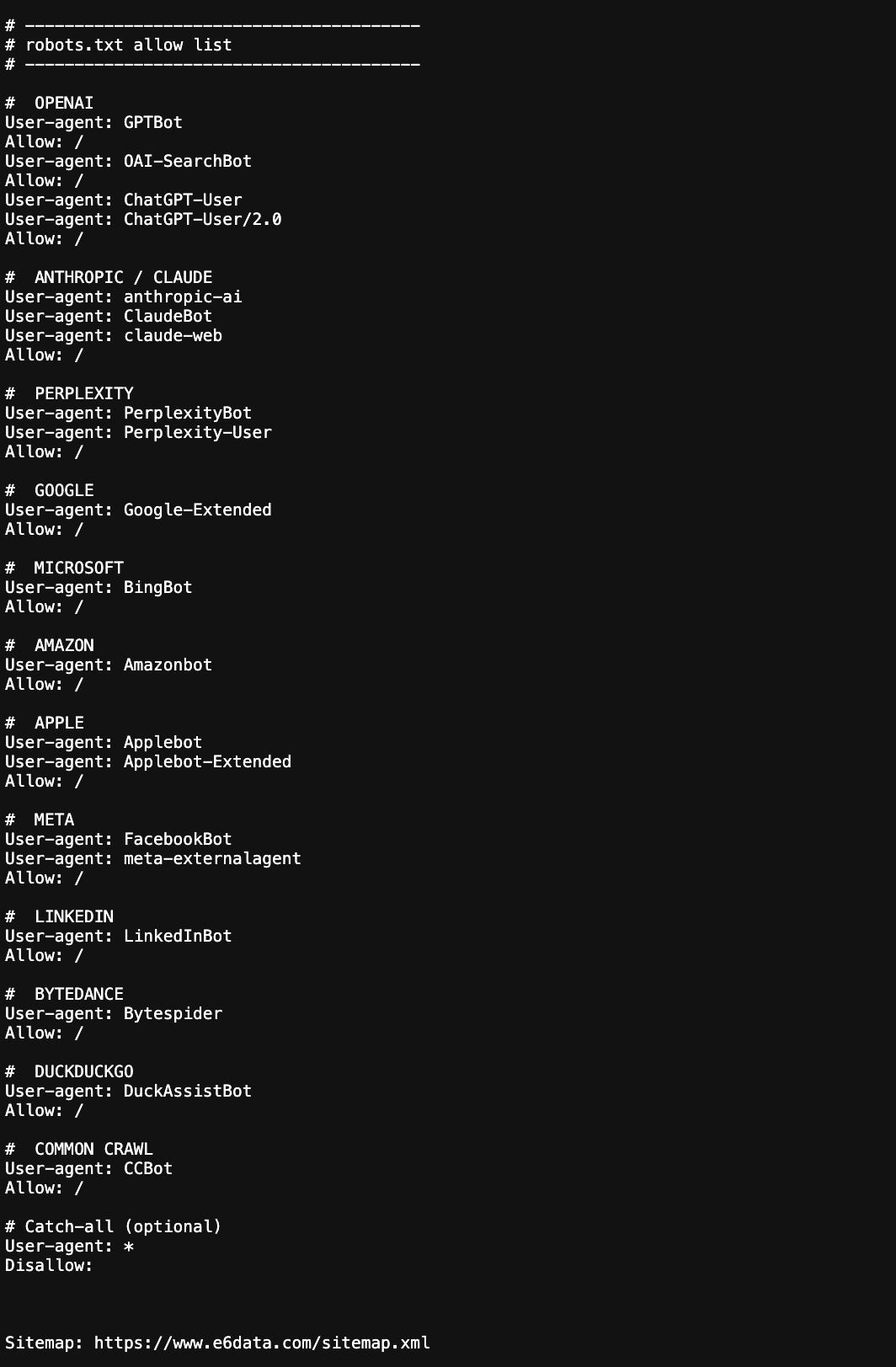
Phrase optimization (natural language queries):
Include variations of how people ask questions in LLMs.
Q&A format structure:
Structure content in question-answer pairs:
4.3: Infrastructure & fast indexing hacks
GitHub Pages indexing hack (for developer marketing)
If you’re targeting developers, GitHub pages get indexed by LLMs significantly faster:
1. Create a GitHub repository for your content
2. Enable GitHub Pages in repo settings
3. Structure as documentation
4. Add technical content (code samples, API docs, integration guides, benchmarks)
Why it works: LLMs prioritize developer documentation from GitHub because it’s typically high-quality, well-structured, and regularly updated.
Documentation pages get scraped faster by LLMs. Convert your docs to a dedicated `llms.txt` format:
Complete technical optimization checklist:
For each piece of content:✅ YAML frontmatter with all metadata
✅ JSON-LD schema (FAQPage + Article/HowTo)
✅ Primary keyword in H1, first 100 words, naturally throughout
✅ Secondary keywords in H2 headers
✅ 10-15 natural language phrase variations for LLM queries
✅ Auto-generated FAQ section (5-7 questions)
✅ Meta description with primary keyword + data point
✅ OpenGraph and Twitter Card tags
✅ robots.txt allows all LLM crawlers
✅ llms.txt file includes page URL
✅ sitemap.xml updated automatically
✅ “Last Updated” timestamp in ISO 8601 format
✅ Author expertise statement
✅ Canonical URL specified
✅ Structured with clear H1 > H2 > H3 hierarchy
Step 5: Scale the system inside Cursor /Claude Code/ QBack (the full setup)
Here’s how to actually implement this inside Cursor (earlier) and QBack.
Forward this to your growth and product marketing friends who are still writing one blog post per week.
The marketers who figure out programmatic content + LLM ranking in 2026 will have an insane advantage over those who wait.
P.S. The technical optimization section (Step 4) is super important. The llms.txt file, robots.txt configuration, and JSON-LD schema are what actually get you indexed. I’ve seen companies create amazing content that never gets cited by LLMs because they skip the technical setup. Don’t skip it.
P.P.S. I also tested the recent bunch of GEO tools that launched. Some of them are straight-up gaslighting – charging premium prices for basic keyword stuffing wrapped in “AI optimization” language. The tools that actually work? The ones that help you structure your existing authoritative content for LLM parsing, not the ones that try to game citations with synthetic content.
Got your back, builders. 🎯
Want more content like this? Follow me on LinkedIn @harshitjain7 / Twitter @harshitqback where I share what’s actually working in AI marketing.